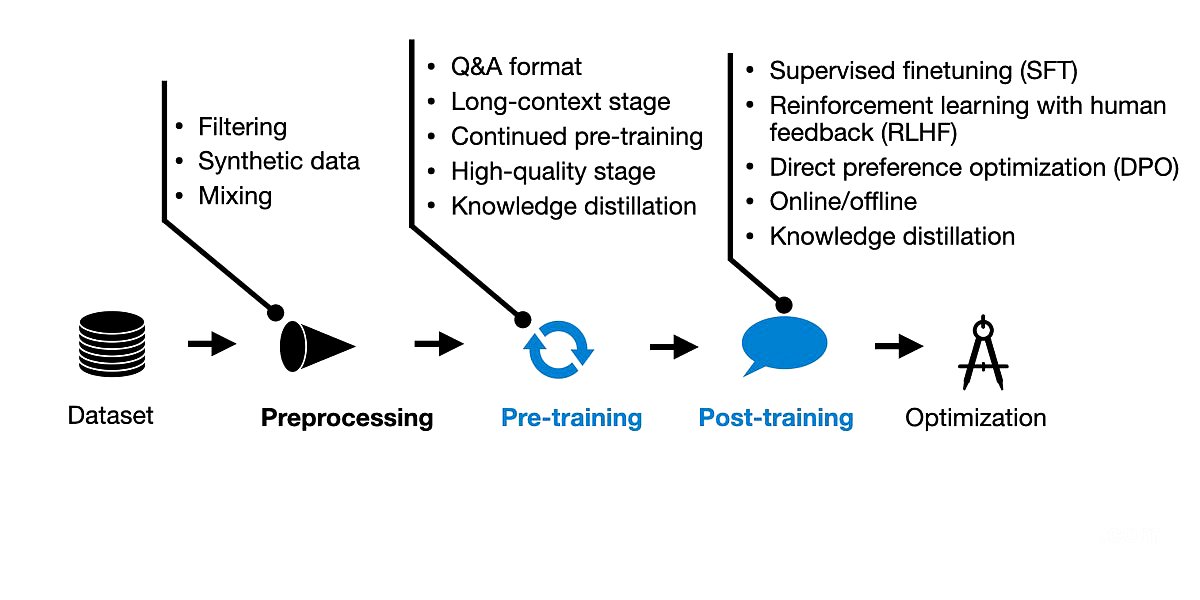
TLDR;
This article explores the latest advancements in pre-training and post-training methodologies for large language models (LLMs). It examines the training pipelines of four prominent LLMs: Alibaba's Qwen 2, Apple's Foundation Models (AFM), Google's Gemma 2, and Meta AI's Llama 3.1. The article highlights the commonalities and differences in their approaches, emphasizing the importance of data quality, multi-stage pre-training, and the use of rejection sampling in post-training.
- All four models utilize a multi-stage pre-training pipeline, including core pre-training, context lengthening, and sometimes high-quality annealing.
- Post-training commonly involves rejection sampling, but there is no consensus on the use of Direct Preference Optimization (DPO) or Reinforcement Learning with Human Feedback (RLHF).
Alibaba's Qwen 2
This chapter focuses on Alibaba's Qwen 2, a powerful LLM family that is competitive with other major LLMs. It discusses the model's specifications, pre-training methods, and post-training techniques.
Qwen 2 models come in five variations, with parameter sizes ranging from 0.5 billion to 72 billion. They excel in multilingual capabilities, supporting 30 languages, and have a large vocabulary of 151,642 tokens. The pre-training process involved training on 7 trillion tokens, with a focus on data filtering and mixing to enhance data diversity. The researchers also used Qwen models to synthesize additional pre-training data and incorporated multi-task instruction data to improve in-context learning and instruction-following abilities. Post-training employed a two-phase approach: supervised instruction fine-tuning (SFT) and direct preference optimization (DPO). The DPO phase involved using an existing dataset and a reward model to select preferred responses for optimization. The chapter highlights the use of synthetic data for both pre-training and post-training, as well as the emphasis on dataset filtering.
Apple's Apple Intelligence Foundation Language Models
This chapter delves into Apple's Foundation Models (AFM), designed for use on Apple devices. It examines the model's specifications, pre-training process, and post-training techniques.
The AFM models come in two versions: a 3-billion-parameter on-device model and a larger server model. They are designed for chat, math, and coding tasks. The pre-training process involved three stages: core pre-training, continued pre-training with a focus on math and code, and context lengthening using synthetic data. The chapter highlights the use of knowledge distillation, where a smaller model is trained on the original training tokens plus the outputs from a larger teacher model. The post-training process involved supervised instruction fine-tuning followed by reinforcement learning with human feedback. Apple introduced two new algorithms for the RLHF stage: Rejection Sampling Fine-tuning with Teacher Committee and RLHF with Mirror Descent Policy Optimization. The chapter emphasizes the comprehensive approach to pre-training and post-training, likely due to the high stakes involved.
Google's Gemma 2
This chapter explores Google's Gemma 2, a set of efficient LLMs designed to improve performance without increasing the size of training datasets. It discusses the model's specifications, pre-training methods, and post-training techniques.
Gemma 2 models come in three sizes: 2 billion, 9 billion, and 27 billion parameters. They feature a large vocabulary of 256k tokens and employ sliding window attention to reduce memory costs. The pre-training process involved training the 27B model from scratch and using knowledge distillation for the smaller models. The chapter highlights the focus on data quality and the use of knowledge distillation. The post-training process involved supervised fine-tuning and reinforcement learning with human feedback. The chapter emphasizes the use of a reward model that is ten times larger than the policy model and the use of WARP, a successor to WARM, for model averaging.
Meta AI's Llama 3.1
This chapter examines Meta AI's Llama 3.1, a powerful LLM family that includes a massive 405 billion parameter model. It discusses the model's specifications, pre-training process, and post-training techniques.
Llama 3.1 models are available in three sizes: 8 billion, 70 billion, and 405 billion parameters. They are trained on a massive 15.6 trillion tokens dataset and feature a vocabulary size of 128,000 tokens. The pre-training process involved three stages: standard initial pre-training, continued pre-training for context lengthening, and annealing on high-quality data. The chapter highlights the use of heuristic-based and model-based quality filtering for data control. The post-training process involved supervised fine-tuning, rejection sampling, and direct preference optimization. The chapter emphasizes the use of model averaging techniques for both the reward model and the SFT and DPO models.
Main Takeaways
This chapter summarizes the key takeaways from the analysis of the four LLMs discussed in the article.
The article highlights the diverse approaches to pre-training and post-training employed by these models. While there are commonalities, such as the use of multi-stage pre-training and rejection sampling in post-training, no single training pipeline is identical. The chapter emphasizes the importance of data quality, the use of knowledge distillation, and the ongoing exploration of different preference tuning techniques. The article concludes that there is no single recipe for developing highly-performant LLMs, but rather a multitude of paths to explore.








