TLDR;
This lecture explores algorithms for data filtering and deduplication, crucial steps in preparing data for training language models. It covers model-based filtering techniques using n-gram models, fastText classifiers, and importance resampling. The lecture also discusses how these filtering methods can be applied to language identification, quality control, and toxicity detection. Additionally, it examines algorithms for exact and near deduplication, including bloom filters and locality-sensitive hashing (LSH), to improve data efficiency and prevent memorisation.
- Explores model-based filtering techniques for data preparation.
- Discusses applications of filtering in language identification, quality control and toxicity detection.
- Examines algorithms for exact and near deduplication to improve data efficiency.
Filtering Algorithms [1:27]
The lecture begins by outlining the basic problem of filtering: given a small target dataset of high-quality data and a large raw dataset, the goal is to find a subset of the raw data that is similar to the target data. The filtering algorithm should generalise from the target data and be extremely fast to run on large datasets. Three methods for implementing this primitive are explored: training an n-gram model, using fastText, and applying data selection with importance resampling.
N-gram Models for Filtering [2:43]
The first method involves training an n-gram model with Kneser-Ney smoothing, often implemented using the CANLM toolkit. N-gram modelling is simple, involving counting the number of n-grams and normalising. The main challenge is sparse counts, which Kneser-Ney smoothing addresses by using lower-order n-grams when data is insufficient for higher-order ones. An example demonstrates using a pre-trained n-gram model to compute the perplexity of different sentences, showing how it assigns higher perplexity to gibberish. CCNET used this approach by sorting paragraphs by increasing perplexity and keeping the top third to create the first LLaMA dataset.
FastText for Filtering [8:39]
FastText, developed by Facebook, is another popular method. It was initially designed for text classification, offering a fast, almost linear classifier. FastText reduces the dimensionality of the vocabulary space before classification, greatly reducing the number of parameters. It extends to n-grams by hashing them into a fixed number of bins to manage the potentially unbounded number of bi-grams. Collisions are accounted for during loss minimisation. FastText is often used for binary classification (good/bad document) and, while fancier models like BERT or LLaMA could be used, the computational cost might outweigh the benefits.
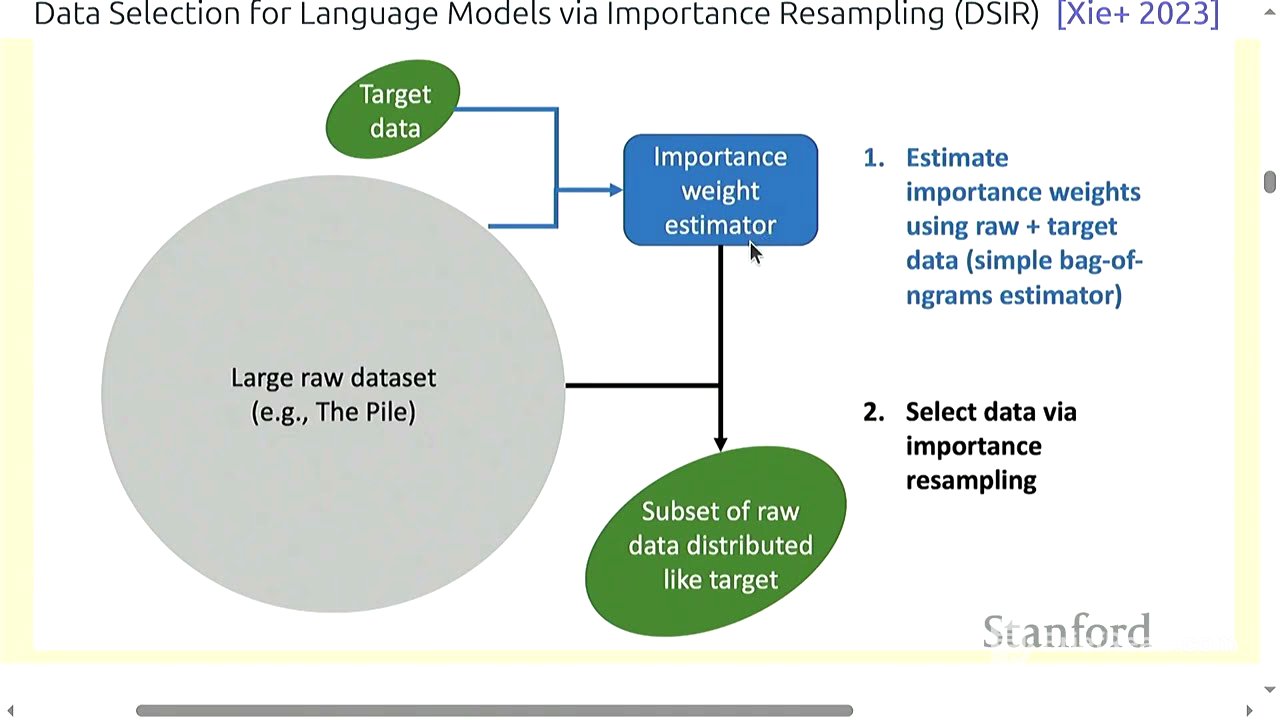
Importance Resampling for Data Selection [13:27]
The third method is data selection using importance resampling. This involves building an importance weight estimator, analogous to the n-gram model or fastText classifier, to obtain a subset of documents. Importance resampling involves sampling from a proposal distribution Q (raw data) when you ideally want to sample from a target distribution P (high-quality data). Weights are computed based on the ratio P/Q, and the data is resampled to balance the distribution. Hashed n-grams are used to estimate the probability of each hashed n-gram, addressing the issue of small target datasets. This approach aims to model the whole distribution for better diversity compared to fastText.
Applications of Data Filtering [23:49]
The lecture transitions to how data filtering machinery can be applied to different tasks, including language identification, quality filtering, and toxicity filtering. For language identification, fastText offers off-the-shelf models trained on multilingual sites. A case study on OpenWebMath demonstrates curating a large corpus of mathematical text by training CANLM and a fastText classifier to predict mathematical writing. Quality filtering involves training a classifier to distinguish high-quality sources from common crawl data. The 51 paper used GPT-4 to determine the educational value of code snippets, training a random forest classifier on the embeddings from a pre-trained model.
Toxicity Filtering [35:14]
For toxicity filtering, the lecture references the Dolma paper, which uses the Jigsaw toxic comments dataset to train fastText classifiers for hate speech and NSFW content. Examples illustrate how these classifiers are used to flag problematic content.
Deduplication Techniques [37:01]
The lecture then addresses deduplication, distinguishing between exact duplicates (due to mirroring) and near duplicates (differing by a few tokens). Near duplicates can arise from terms of service, licenses, or paraphrasing. Deduplication improves training efficiency and avoids memorisation. The design space for deduplication involves considering the unit of deduplication (sentence, paragraph, document), the matching criteria (exact match, fraction of common sub-items), and the action taken (remove all instances or all but one).
Exact Deduplication [44:28]
Exact deduplication involves computing a mapping from hash value to the list of items with that hash and keeping one item from each group. This method is simple, high precision, and easily parallelised. C4 uses this approach with three-sentence spans. Bloom filters offer an efficient, approximate method for representing sets, allowing for memory-efficient set membership queries. Bloom filters can have false positives, but the false positive rate can be controlled by setting hyperparameters.
Bloom Filters [46:41]
A bloom filter uses a bit array and multiple hash functions to map items to bins. Querying involves checking if all K hash functions return a set bit. The false positive rate can be reduced by using more hash functions. The lecture provides a mathematical analysis of bloom filters, showing how to compute the optimal number of hash functions and the resulting false positive rate.
Approximate Deduplication and MinHash [58:55]
Approximate deduplication requires a similarity measure, such as Jaccard similarity, which is the ratio of the intersection over the union of two sets. Two documents are considered near duplicates if their Jaccard similarity exceeds a threshold. MinHash is a hash function with the property that the probability of a hash collision is exactly the Jaccard similarity. MinHash involves hashing all elements of a set and taking the minimum element.
Locality Sensitive Hashing (LSH) [1:05:07]
Locality Sensitive Hashing (LSH) sharpens the probabilities around the threshold. LSH involves breaking up N hash functions into B bands of R hash functions and declaring that A and B collide if, for some band, all hash functions return the same value. The lecture provides an analysis of the probability of collision in LSH and demonstrates how to tune the parameters B and R to achieve a sharp sigmoid curve mapping similarity to the probability of collision. An example from a paper using MinHash LSH shows how they set B and R to achieve a threshold of 0.99.
Summary and Conclusion [1:16:49]
The lecture concludes by summarising the algorithmic tools for filtering (n-gram models, linear classifiers, importance resampling) and deduplication (hashing, bloom filters, MinHash LSH). It emphasises the importance of spending time with the data to build intuitions about what works and what doesn't.