TLDR;
This tutorial provides a comprehensive guide to understanding and implementing a machine learning-based DDoS attack classifier. It covers the theoretical concepts behind DDoS attacks, the complete project pipeline from data collection to model evaluation, and a detailed code explanation using Python. The tutorial aims to equip viewers with the knowledge and practical skills to build and evaluate machine learning models for DDoS attack detection.
- Explanation of DDoS attacks and their impact on network resources.
- Step-by-step guide to building a DDoS attack classifier using machine learning.
- Comparison of different machine learning models (Random Forest, Logistic Regression, Neural Network) for DDoS attack classification.
Introduction to DDoS Attacks and Machine Learning Classification [0:00]
The tutorial introduces the concept of DDoS (Distributed Denial of Service) attacks and explains how machine learning can be used to classify these attacks. It outlines the project pipeline, which includes data collection, pre-processing, data analysis, data splitting, model training, and model evaluation. The goal is to train three machine learning models (Random Forest, Logistic Regression, and Neural Network) to classify DDoS attacks and compare their performance.
Project Pipeline: Data Collection and Pre-processing [0:52]
The initial stage involves gathering labelled data, essential for supervised machine learning. The collected data undergoes pre-processing to handle missing values, convert categorical data into numerical formats, and clean the dataset. This ensures the data is suitable for training machine learning models.
Data Analysis and Splitting [2:24]
The data analysis phase focuses on exploring the data to identify patterns and understand its distribution. Following this, the data is split into training (70%) and testing (30%) sets. The training data is used to train the machine learning models, while the testing data is used to evaluate their performance.
Model Training: Random Forest, Logistic Regression, and Neural Network [4:00]
Three machine learning models are trained: Random Forest, Logistic Regression, and a Neural Network. The Random Forest model is built from multiple decision trees, while Logistic Regression is used for binary classification. The Neural Network model consists of interconnected layers of nodes. The tutorial provides a brief overview of each model and suggests resources for further understanding.
Model Evaluation and Comparison [5:18]
The trained models are evaluated using the testing data, and their performance is measured using metrics such as accuracy, F1 score, precision, recall, and confusion matrix. ROC curves are also calculated for each model. The accuracy of the three models is compared to determine which model is best suited for classifying DDoS attacks. The best model is then selected for use on real data.
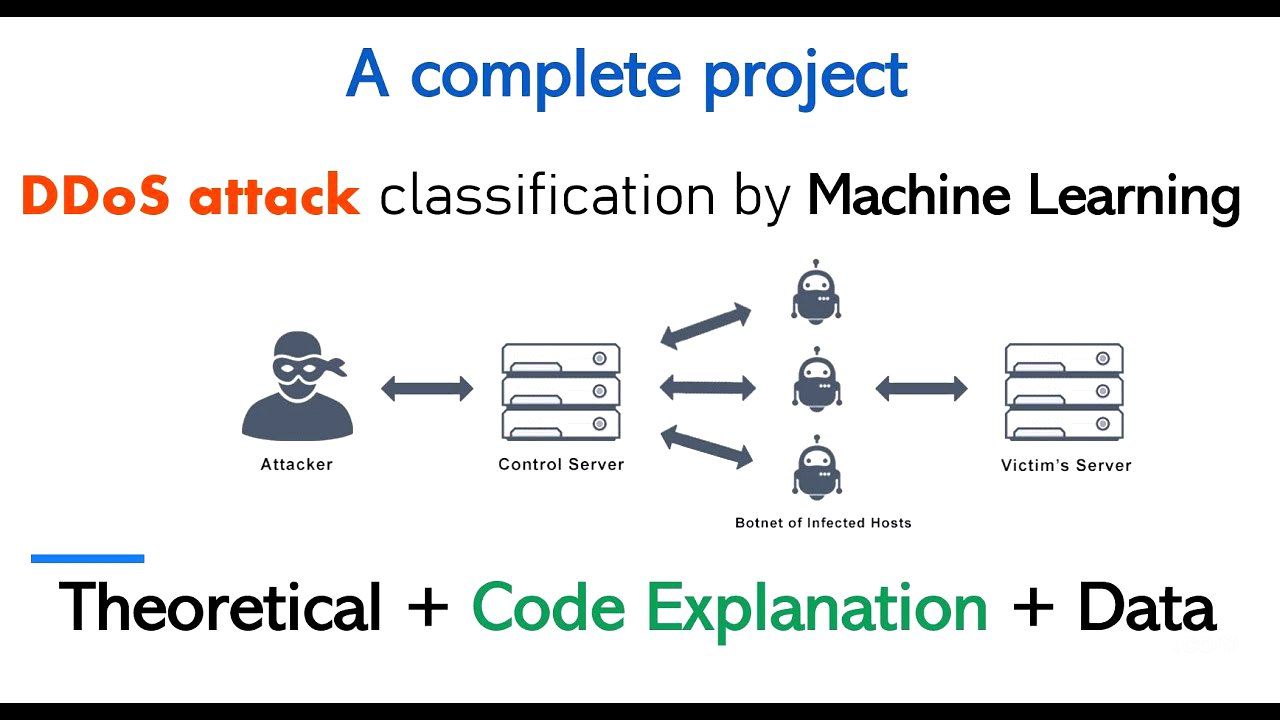
Understanding DDoS Attacks [6:41]
A DDoS attack involves multiple systems flooding a victim's bandwidth or resources with traffic, often resulting from compromised systems. The attacker generates a large amount of traffic to overwhelm the victim's network, causing systems to hang and disrupting network services.
Data Set Selection and Description [8:31]
The tutorial highlights the importance of using a reliable data set for training the machine learning models. It references a research paper that reviews various DDoS attack data sets and selects the CICIDS2017 data set for this project. The data set was captured over five days and includes various network traffic features. The tutorial provides links to access the data set and the research paper.
Code Explanation: Setting Up the Environment and Importing Libraries [11:57]
The code explanation begins with setting up the coding environment and importing the necessary libraries, including pandas, NumPy, matplotlib, and scikit-learn. These libraries are used for data manipulation, numerical computations, plotting graphs, and implementing machine learning models.
Importing and Exploring the Data [20:28]
The data is imported using the pandas library, and the first three rows of the data set are displayed to provide a glimpse of the data. The data set contains 79 columns, with one column representing the target variable (label) and the remaining columns representing the input variables.
Data Pre-processing: Cleaning and Formatting [23:49]
The data is pre-processed to remove spaces from column names and identify unique labels in the data set. Null values are identified and removed from the data set. The tutorial also discusses how to handle null values represented by different characters, such as "INF".
Data Conversion and Analysis [31:06]
The label column, which contains categorical data (benign and DDoS), is converted into numerical values (0 and 1). Histograms are plotted to visualise the distribution of labels and other features in the data set. The describe function is used to provide statistical information about the data set.
Data Splitting: Training and Testing Sets [37:28]
The data is split into training and testing sets using the train_test_split function from scikit-learn. The input features (X) and target variable (Y) are separated, and the data is split into 70% training and 30% testing sets.
Model Training: Random Forest [43:35]
The Random Forest model is trained using the training data. The model is initialised with 50 estimators (trees), and the fit function is used to train the model. The tutorial explains the three main steps for training a machine learning model using scikit-learn: initialising the model, training the model, and predicting the output.
Feature Importance and Model Evaluation [47:02]
The feature_importances_ function is used to identify the most important features for the Random Forest model. The tutorial also explains how to visualise the decision-making process of the Random Forest model. The model is evaluated using the testing data, and metrics such as accuracy, F1 score, precision, recall, and confusion matrix are calculated.
Model Training and Evaluation: Logistic Regression [53:17]
The Logistic Regression model is trained and evaluated using the same process as the Random Forest model. The tutorial highlights the simplicity of training a Logistic Regression model using scikit-learn. The model's performance is measured using the same metrics as before, and the confusion matrix is plotted.
Model Training and Evaluation: Neural Network [54:48]
A Neural Network model is trained and evaluated. The model consists of one hidden layer with 10 neurons. The tutorial explains how to customise the model by adding more layers and neurons. The model's performance is measured, and the confusion matrix is plotted.
Model Comparison: ROC Curve and AUC [56:46]
The tutorial explains the concept of ROC curves and AUC (Area Under the Curve) as a way to compare the performance of different machine learning models. The predict_proba function is used to obtain the probabilities of each class, and the AUC is calculated for each model. The model with the highest AUC is considered the best-performing model.








